This site uses advanced css techniques
The Evolution™ Payroll Service Bureau system from iSystems, LLC requires several servers on the backend to handle the middle and database tiers, and there's been an ongoing discussion on the evo-tech mailing list about the effects of HyperThreading on the performance of these two machines.
This report, which was originally provided to iSystems technical staff, means to shed light on the effects of HT on Evolution database server.
HyperThreading is technology from Intel which provides a second virtual CPU in their Pentium processors. It's not a complete second processor core, but a second set of registers which the CPU can use while the first set is busy.
For some applications, HyperThreading can provide a moderate performance boost by making use of otherwise-idle processor time, while for other applications it either makes no difference or (paradoxically) actually hurts performance due to disruption of the L2 cache.
We used a Dell 1850 rackmount server with this configuration:
The two physical CPUs provide four hyperthreaded ones. We had similar results with an older Dell system, but it had very poor RAID 5 write performance: this skewed the results.
We have written "multithreaded" (really multiprocess, but we use the other term for clarity) programs that do various things with Evo. The program builds a work list for db backup/restore, or db patching, and then manages up to N subprocesses ("threads"). It seems silly to have a multiprocessor machine and not use it, so this mechanism has worked really well.
For the Franklin DB update, Pat W actually used our script for patching because it worked so well. Garfield provided a poor Python patcher, so our perl one has been a popular replacement:
When doing a routine cleanup (backup and restore), these are the commands that get run:
rm -f CL_222.gbk gbak -backup -transportable -limbo -garbage -ignore \ -user SYSDBA -pass XXXXX CL_222.gdb CL_222.gbk mv -f CL_222.gdb CL_222.tmp gbak -replace -page_size 8192 -user EUSER -pass XXXXX CL_222.gbk CL_222.gdb chown firebird:firebird CL_222.gbk CL_222.gdb rm -f CL_222.tmp
The processes used have been fine-tuned for years to properly handle things like a root-owned .gbk file laying around, or something going wrong and destroying the existing .gdb file. This gets all the right kinds of file/db ownership right too.
The whole set of commands for one file is run as a subprocess, and when it exists, another one is launched. This is NOT the same as splitting the files into two directories, because (a) you don't have to do the work, and (b) if the first half finishes early, it helps by working on the second half.
So what's the limiting factor here? Running with --nthreads=2 is faster than --nthreads=1, but at some point adding more "threads" just adds more administrative overhead with no real benefit. To test it, we rean this unload process many times with varying parameters:
#!/bin/sh
for th in 1 2 4 8 1 2 4 8
do
evo-loadtool --threads=$th --reload --verbose *.gdb
sync ; sleep 20; sync; sleep 10
done
This was in a test directory (no active files) on an otherwise idle system, and we used DB files which were collectively much larger than system RAM to avoid the buffer-cache affecting the timing. Each 1/2/4/8 was run twice and the values averaged. Both runs of 1/1 2/2 4/4 8/8 showed VERY close correlation to each other.
Then we enabled HT and ran it again, and this is what we get as a result. This shows the time per file (total runtime divided by 103 files) with the number of threads:
| Number of Threads |
Seconds per File | Improvement w/ HT |
|
|---|---|---|---|
| HT off | HT on | ||
| 1 | 22.41 | 22.95 | -2.40% |
| 2 | 12.24 | 12.57 | -1.47% |
| 4 | 10.77 | 9.56 | +11.23% |
| 8 | 10.54 | 8.79 | +16.67% |
We draw two conclusions from this:
Adding more threads makes it run faster, but it's interesting to see where the dropoff happens. Looking at the performance boost of each transition (say, going from 2 to 4 threads) shows that at some point, there's no improvement:
Without HT: threads 1 » 2 1.83X improvement 2 » 4 1.14X improvement *overloading CPU 4 » 8 1.02X improvement *overloading CPU With HT: threads 1 » 2 1.83X improvement 2 » 4 1.31X improvement 4 » 8 1.09X improvement *overloading CPU
If we ran one more (8 » 16) we'd expect that to show no improvement on either one.
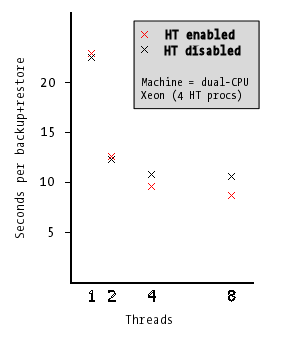
Showing this graphically (on the right):
We suspect that graphing the first derivative of each line would show this a bit more vividly, but this was plenty enough to convince ourselves that HT was worth the effort.
To put these numbers in context: when doing the full load/unload with 8 threads on 103 files:
15:07 HT 18:03 no HT
This was not a synthesized test, either: we really do run this very same process periodically to tidy up our data files, and though we'd rather have more real CPUs, HT is giving 3 minutes for free. We'd imagine that it helps the patch process similarly.
Our research has been with one kind of test — backup and restore — and we have made no measurement of performance with other types of loads. We'd imagine that locking issues with multiple processes accessing the same file might present a less favorable usage pattern.
We also believe that the Linux 2.6 kernel provides substantially better support for HyperThreading than Red Hat 9's 2.4 kernel.
We understand that iSystems recommends disabling HyperThreading on the Windows middle-tier system because it confuses the processor scoring, but so far we have found no downside of HT on the database servers.
Though not specifically weighing on in the Evolution issues, these resources discuss HyperThreading from various technical points of view.
This Evo Tip is not produced or endorsed by iSystems, LLC.
First published: 2005/11/19
![[Steve's Email]](/images/steve-email.gif)